
Data Warehouse et Data Lake, quand 1 + 1 > 2
Les termes data warehouse (DW ou entrepôt de données) et data lake (DL ou lac de données) sont souvent utilisés pour parler du stockage des données massives, mais ils ne sont pas interchangeables. Définissons ces deux concepts, leur combinaison et leur utilisation concrète pour une entreprise.
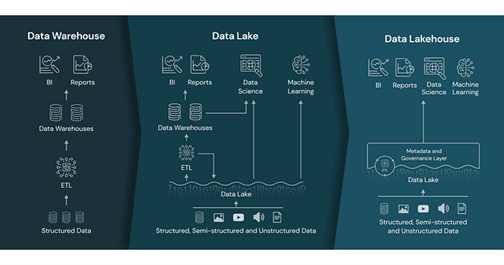
La différence entre un Data Warehouse et un Data Lake
Data Warehouse
Un DW est un référentiel de données structurées et filtrées qui ont déjà été transformées dans un but spécifique. Il s’agit d’une plateforme utilisée pour collecter et analyser des données provenant de multiples sources hétérogènes. Les données stockées dans un DW sont généralement nettoyées, organisées et optimisées pour répondre aux besoins métier.
Voici quelques caractéristiques clés :
- Structure des données : Les données stockées dans un DW sont transformées et nettoyées. Elles sont prêtes à être utilisées pour la prise de décisions.
- Utilisateurs ciblés : Les spécialistes et les analystes métier accèdent aux données du DW.
- Accessibilité : L’accès aux données est plus complexe et coûteux, mais les requêtes sont optimisées.
Prenons comme exemple une grande entreprise de vente au détail. Elle utilise un DW pour stocker et analyser les données de ses ventes, des inventaires, et des clients. Les spécialistes du marketing peuvent accéder aux rapports pour prendre des décisions sur les promotions et les campagnes publicitaires.
Dans cet exemple, le DW contient des données transformées, telles que le chiffre d’affaires par région, les marges de profit, et les tendances saisonnières. Ces informations sont nettoyées et organisées en amont pour faciliter l’analyse des analystes de marketing et/ou de ventes.
Data Lake
Un data lake est un vaste gisement de données brutes dont le but n’a pas été précisé encore. Il stocke des données non transformées, qu’elles soient structurées, semi-structurées ou non structurées.
Voici quelques caractéristiques clés :
- Structure des données : Les données brutes sont malléables et idéales pour le machine learning (apprentissage automatique). Cependant, elles nécessitent une gouvernance rigoureuse pour éviter de devenir un « marécage » de données.
- Utilisateurs ciblés : Les scientifiques de données et les experts en analyse de données accèdent aux données du data lake.
- Accessibilité : L’accès est facile et les mises à jour sont rapides, mais les modifications sont plus complexes et coûteuses.
Prenons cette fois-ci l’exemple d’une entreprise de médias sociaux. Elle collecte des milliards de tweets, de photos et de vidéos chaque jour. Plutôt que de les transformer immédiatement, elle les stocke dans un DL.
Les scientifiques de données peuvent explorer ces données brutes pour détecter des tendances, analyser les sentiments des utilisateurs, ou prédire les sujets viraux. Par exemple, ils pourraient rechercher des hashtags populaires liés à un événement sportif ou à une élection.
Combiner un Data Warehouse et un Data Lake : Le meilleur des deux mondes
Maintenant on combine deux concepts, c’est-à-dire la flexibilité et l’évolutivité d’un data lake avec la gestion et les transactions ACID d’un data warehouse. Le résultat ce qu’on appelle désormais de data lakehouse ou tout simplement, lakehouse.
Data Lakehouse
Le lakehouse représente une nouvelle approche unifiée de la gestion et de l’analyse des données en fusionnant les meilleurs éléments des lacs de données et des entrepôts de données au sein d’une seule plateforme. Contrairement aux architectures de données traditionnelles, qui reposent sur des systèmes distincts pour le stockage et le calcul, le lakehouse dissocie le stockage du calcul, permettant aux organisations d’évoluer indépendamment et d’optimiser l’utilisation des ressources.
Les avantages d’une architecture Lakehouse
Bill Inmon, largement considéré comme un des pères de l’entrepôt de données, est un fervent défenseur de l’architecture lakehouse.
Voici quelques-uns de ses points de vue sur les avantages de cette architecture :
- Flexibilité : Il souligne que cette approche offre une grande flexibilité en permettant de stocker une grande variété de données, structurées et non structurées, dans leur format natif. Cela permet aux entreprises de capturer et d'exploiter des données provenant de sources diverses sans avoir à les transformer immédiatement.
- Évolution : Grâce à l'utilisation de technologies de stockage massif comme Hadoop et Spark, les architectures lakehouse peuvent facilement évoluer pour prendre en charge des volumes de données croissants sans compromettre les performances.
- Analyse en temps réel : Cette architecture met en avant la capacité de prendre en charge l'analyse en temps réel, permettant ainsi aux entreprises de prendre des décisions basées sur des données en temps réel.
- Coût-efficacité : En combinant les capacités de stockage peu coûteuses des data lakes avec les fonctionnalités analytiques des entrepôts de données traditionnels, les architectures lakehouse peuvent offrir une solution plus rentable pour la gestion et l'analyse des données à grande échelle.
Pourquoi utiliser une architecture lakehouse : L’exemple d’un commerce électronique
Imaginons une entreprise de commerce électronique qui souhaite améliorer son expérience client et optimiser ses opérations en utilisant une architecture lakehouse.
1. Collecte de données en temps réel
L'entreprise collecte en continu des données provenant de son site web, de ses applications mobiles, de ses interactions avec les clients sur les réseaux sociaux, ainsi que des données transactionnelles provenant de ses systèmes de gestion des commandes et des inventaires. Ces données sont stockées dans un lac de données dans leur format brut, sans transformation initiale.
2. Analyse en temps réel
En utilisant des outils d'analyse en temps réel basés sur des technologies comme Apache Spark, l'entreprise peut analyser les données en continu pour détecter les tendances émergentes, les comportements des clients en temps réel, et les problèmes potentiels sur son site web ou ses applications.
3. Intégration avec l'entrepôt de données
Les données pertinentes sont ensuite extraites du lac des données et transformées selon les besoins pour être chargées dans le DW traditionnel. Cela permet d'effectuer des analyses plus poussées, des rapports périodiques et des requêtes complexes qui nécessitent des données nettoyées et structurées.
4. Prise de décision basée sur les insights
Les analystes et les décideurs utilisent les données stockées dans l'entrepôt de données pour prendre des décisions stratégiques, telles que l'optimisation des campagnes marketing, l'amélioration de l'expérience client, la gestion des stocks, et l'identification de nouvelles opportunités commerciales.
5. Formation de modèles prédictifs
Les données du DL et de l'entrepôt de données sont également utilisées pour former des modèles prédictifs et des algorithmes d'apprentissage automatique. Ces modèles peuvent être déployés en production pour la personnalisation des recommandations de produits, la détection de fraudes, la prévision de la demande, et d'autres cas d'utilisation.
Une combinaison gagnante ?
Le concept de data lakehouse est en effet fascinant et peut sembler paradoxal à première vue. Pourtant, il illustre comment la combinaison d’un data warehouse et d’un data lake peut créer une somme plus grande que leurs parties individuelles. C’est pourquoi, dans ce cas, 1 + 1 > 2 !
Rédaction par Sanzio Castor, Analyste de données/Data Analyst
Références
Building the Data Lakehouse par Bill Inmon
What is a Data Lake? https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-a-data-lake/
Data lake vs data warehouse https://www.talend.com/fr/resources/data-lake-vs-data-warehouse/
A quoi sert un Data Lakehouse? https://www.oracle.com/fr/big



